This article is a brief introduction to the REpresentational State Transfer (REST) architecture. It is intended for aspiring/junior software developers and other technical professionals who would like to have a better understanding of REST.
Representational State Transfer is a system architectural style enabling the creation and utilization of web services. Services compatible with REST are referred to as “RESTful.” This is common among microservices, which allows for compatibility between multiple systems. It is a stateless protocol, meaning that requests and responses do not rely on prior messages.
Example
One common use for RESTful web services is to access data stored in a database. To use a REST API, the endpoint URL and its available resources and actions must be known. For example, an endpoint might allow GET actions to retrieve and display data about movies.
Request
In this example, a client sends a GET request (which is a safe method that cannot modify the target system) to the API endpoint, specifying the desired response media type in the header. There are a variety of ways to send a request programmatically or through tools such as curl or Postman, but for now we will focus on the concepts.
This request assumes we know the movie ID. The specified ID (12345) is requested from the /movies/ endpoint from movie.example.com.
GET /movies/12345 HTTP/1.1 Host: movie.example.com Accept: application/json
Response
A successful response includes a HTTP 200 OK status, and the type and length of the content. The body of the response follows the header. In this case, the data returned is formatted as JSON.
HTTP/1.1 200 OK
Content-Type: application/json
Content-Length: ...
{
"movie": {
"movie_id ": 12345,
"movie_title": "The Matrix",
"genres": [
"action",
"adventure",
"sci-fi"
],
"links": {
"update": "/movies/12345/update",
"delete": "/movies/12345/delete",
}
}
}
The response body includes details about the requested movie (12345), as well as links to additional endpoint actions such as updating or deleting this specific record.
Characteristics of system design
There are a few fundamental characteristics of system architecture that influenced the development of REST.
Colloquially referred to as the “-ilities,” there are several key characteristics of a solid technical architecture. Many of these principles are related to each other as they must work together to achieve their intended functionality. However, these characteristics do sometimes force design trade-offs due to competing needs.
The following are characteristics of a high-quality system architecture:
- Performance
- Scalability
- Simplicity
- Mutability
- Visibility
- Portability
- Reliability
Performance
Technical performance (such as system, network or storage throughput) plays an important role in
performance from the perspective of the overall system. However, a well-architected system is primarily focused on user-perceived performance – i.e., minimizing the latency between interaction and response.
Scalability
A well-designed system should be able to adjust to demand. Without scalability, an increase in users can negatively impact the overall performance of a system. By simplifying and decentralizing internal components, the system should be able to redistribute load across multiple service providers.
Simplicity
Simplicity enables each component of the system to develop independently and makes changes easier for developers to implement.
Mutability
Sometimes referred to as Extensibility, this quality attribute is an important part of system design that makes future changes easier, potentially without affecting the system’s operational status.
Visibility
Visibility is the concept of transparency between modular components, as well as the function of being able to moderate the relationship between them.
Portability
For a system to be portable, it should be able to operate in multiple environments or otherwise unaware of the architecture’s underlying hardware or software platform.
Reliability
Reliability is all about minimizing the Mean Time Between Failure – the ability for a system to be resilient in the face of total or partial failures. This can be supported by avoiding design bottlenecks, implementing redundancy or monitoring systems, and creating operational procedures such as a maintenance schedule.
Implementation of REST
Client-server model
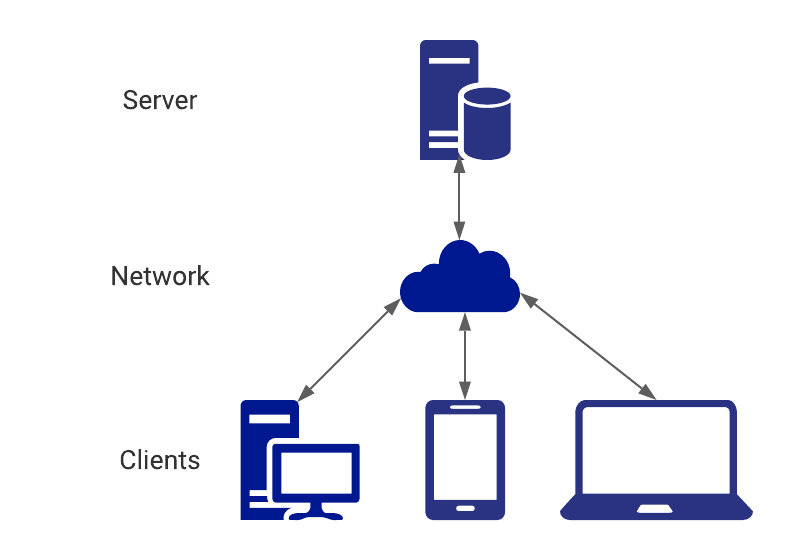
The Client/Server model is a conceptual framework for separating tasks between a service provider (server) and a requester (client). In the context of REST, a server is responsible for storing, accessing and performing operations on data or resource, while a client is responsible for requesting and subsequently formatting the desired data or resources.
Stateless
Stateless communication requires that requests made to the server includes all relevant information to understand the request. It must be independent from any previous messages, as clients are responsible for managing state. This is a design trade-off as it results in a potential increase of network requests, but supports the architectural attributes of visibility, reliability and scalability.
Caching
Certain data provided by the server can be marked as cacheable, such that the client can reuse that data for follow-up requests. This helps alleviate the architectural drawbacks of stateless communication. However, it can negatively impact reliability as cached data is susceptible to become stale or unsynchronized from the server.
Layered system
In the same way that the client/server model supports separation of concerns, the REST architecture allows for a layered system to prevent components from managing things outside of its own scope. Additional layers for security and network management (e.g., proxies, load balancers, firewalls and other intermediary devices) can be introduced to further separate business logic from clients who are unaware of the internal workings.
Uniform interface
Broadly speaking, “RESTful” architectures are meant to simplify and decouple the architecture to allow each component to be developed independently. But they are also meant to provide a uniform interface. There are four additional constraints that help deliver a uniform interface.
Resource identification
Because data can be presented in multiple formats (HTML, XML, JSON) which are separate from the server’s stored data, resources must be identified when requested from the server.
Resource manipulation via representation
Once a client has received a resource from the server, it has everything necessary to make changes to that resource (assuming sufficient permission to do so). For example, a resource containing a list of customers includes the customer IDs, which can be used to construct an additional request to modify or delete that customer’s data on the server.
Self-descriptive messages
Each request provides the server with all relevant information necessary to complete the client’s desired operation.
Hypermedia as the engine of application state
Responses from the server should include links that allow a client to dynamically discover additional operations that are available to it. For example, if a client has requested to read details about a customer ID, the server would respond with links to modify or delete that record in the server database.